PSYCH 221 FINAL PROJECTInterpolation Methods |
|
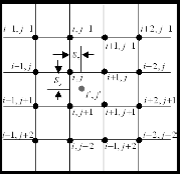
The first straigthforward approach was to interpolate. We began by trying several commonly used interpolation schemes: bicubic, tricubic, hermite, and spline. We then discovered a paper on image resampling using an adaptive bicubic method, local feature bicubic interpolation: Cubic interpolation is one of the most common interpolations schemes since it is the simplest interpolation method that "offers true continuity between the segments."[2] 2 The 1D cubic interpolation formula for estimating the value between y1 and y2 is seen above. To apply this formula in two directions, x and y, independently, bicubic interpolation is performed. To attempt to get even more precise interpolation the formula can be applied not only to the x and y direction but also across the diagonals, tricubic interpolation. Local Feature Based Bicubic Interpolation:
Reading the literature we found that there are both non-adaptive and adaptive interpolation schemes. The adaptive interpolation schemes attempt to factor in whether the surrounding pixels represent an edge, smooth flat region, or a textured area. These adaptive interpolation methods we found are proprietary and designed for image enlargement. One scheme we came across attempted to use the local features to adapt the bicubic interpolation method. They understood that the bicubic interpolation method has a blurring problem. Therefore, they used the local asymmetry of the features and the local gradient of the surrounding pixels to remove this blurring in their own interpolation method. There were three stages to their solution. The first stage used the local asymmetry of the image features, but failed because it performed poorly with peaks and troughs. The second stage used the local gradient but failed because it sometimes overshot the interpolated pixel value. Therefore, finally they combined both approaches to mitigate each stages problems and come up with a ‘superior’ solution that did remove the blurring problem of the bicubic interpolation method.
Hermite interpolation is very similar to cubic interpolation in that it requires four points and offers high degree of continuity between the points. Background and Theory:
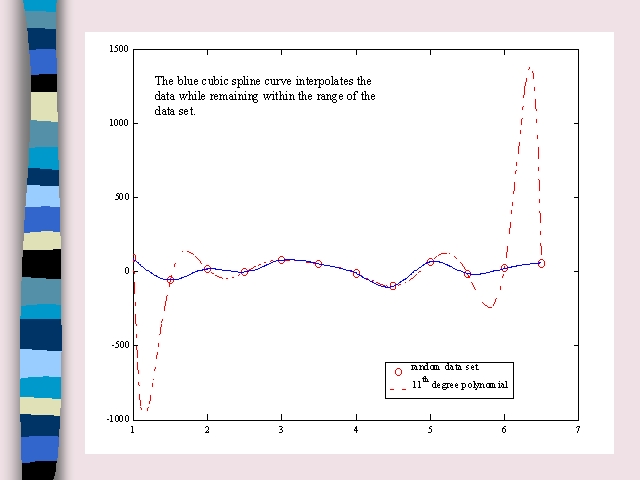
As can be seen, the 11th degree polynomial makes huge jumps after the first and before the last point which adds to the error profile of the interpolation scheme.
|
|||||||||||||||||||||||||