| Introduction | Go back to the index | Photo processing |
In the recent years, great improvements in object recognition have been achieved. In this field, it is especially interesting the research in [1], which tries to improve object recognition by including context information, and using AI systems trained with large labeled photos databases.
A good introduction to the object detection techniques can be obtained by looking at [2]. That course presents some object detection techniques that do not take the context into account.
The simplest object detection technique is the one called "bag of words" [3]. That technique consists in dividing a reference image, for example a face, in small patches called features. Then we create different sets of features (bags) for each object category, each containing patches from that object. Once we have all the bags, we take the features from all of them, correlate them with the image under study and see which ones appear more frequently. Comparing that result to the original bags, we can classify the object.
The main problem with the "bag of words" is that it does not take into account the shape of the object. The reference objects are divided in patches without any information of the relative position between them. This problem is solved in the part-based models as the one presented in [4]. In this model, we do not only extract patches form the reference object, but we also create models of the relative position between the patches, assigning probabilities to each of the possible positions. For example, the following shows the features extracted from a face, and the relative spatial probability density functions for each of the patches:

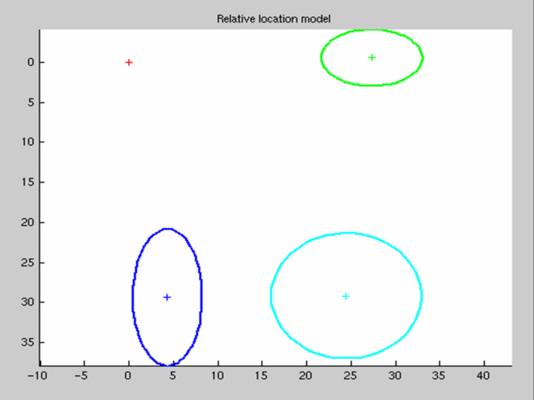
Having created this model, the features are correlated with the image that is being analyzed, and the local maxima for each patch are calculated as shown in the following image:
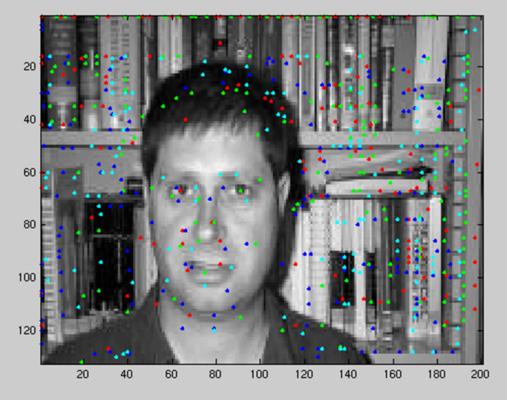
From all those local maxima the set of 4 that better matches the face model, taking into account the relative spatial probability densities, must be extracted. All the possible sets are compared with this model, and the best one is chosen. The result is shown in these images:
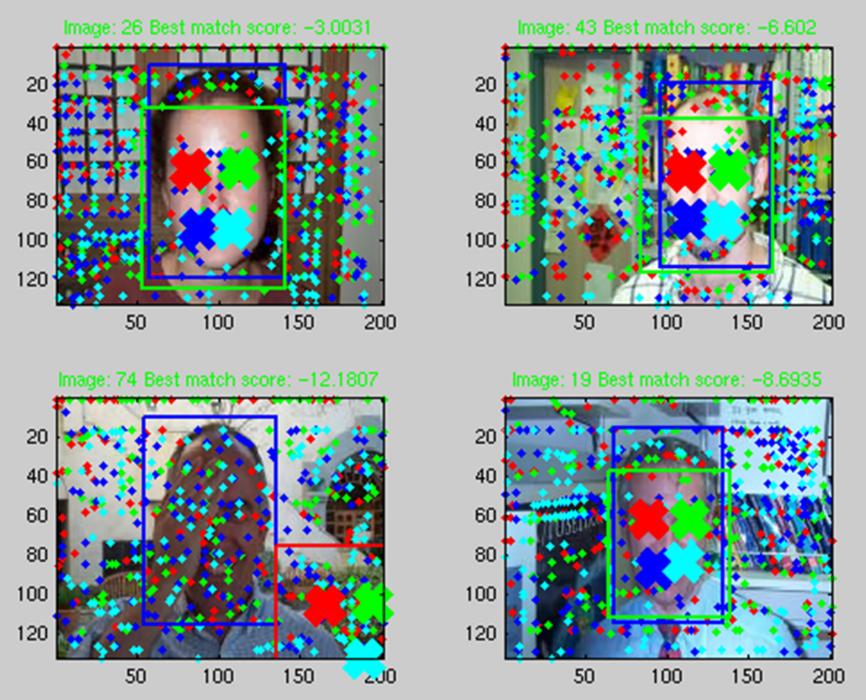
While from the previous images, it is obvious that this method can be used for face recognition, it is the opinion of the author of this report that it is suboptimal for this purpose. The shape models are extremely useful for objects whose shape changes significantly, like a human body by moving its limbs, however, the relative positions of the face features can not change significantly, making the model useless. Once the model is useless, having small patches instead of correlating the image with a whole face produces worse results. Moreover, the method shown above does not take into account the color information of the faces, which is very useful as the skin color is very close between all the faces (at least from the same race).Furthermore, the algorithm seems harder to extend for multiple face recognition in a single photo.
For this reason, all these methods were abandoned, and a new face recognition algorithm was built from scratch for this project.
| Introduction | Go back to the index | Photo processing |