

< Figure: 8 bit "car" image >
< Figure: 3 bit "car" image >
< Figure: Center of mass difference >
The basic idea and the motivation for
it is described in this section. Also the assumptions and application of
the idea are describe.
Instead of dividing the whole image into meaningless blocks, we can divide the image into objects. This makes sense because an object( or at least a portion of an object) have a tendency to have the same optical flow. A simple way without increasing too much complexity is to divide an image into several regions where luminance values are similar. Even though an object is divided into multiple regions where the brightness is similar, it does not cause a huge trouble since each subdivided regions will have the same motion because they belong to the same object. The good thing about this is that by dividing the image into objects, we don't have to apply the spatial coherence constraint described earlier.
Another motivation comes from the fact
that the algorithms should be simple enough so that it is implementable.
One application in mind when thinking about this idea was a high speed
imaging. For high speed imaging, assuming that the object moves very slowly
compared to the sampling rate, the brightness conservation constraint is
met automatically. One drawback of high speed imaging application is that
the complexity should be low. Since we have an enormous amount of image
data when we sample at high rates, it is essential that the complexity
of the algorithm is low.
< Figure: 8 bit "car" image >
< Figure: 3 bit "car" image >
< Figure: Center of mass difference >
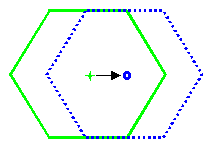
Now that we have segmented the image
into different regions, we would like to find out how much each region
moved until the next frame. The idea here is to calculate the location
of the center of mass for each regions and see how much the center of mass
moved. To reduce complexity, instead of summing up all the horizontal and
vertical cooardinates of pixels within a region, we can integrate the horizontal
and vertical cooardinates of pixels that are on the edge of each regions.
![]()
Center of mass only gives the information
about translational movement. If an object is moving toward or away from
the camera, then the size of each object and hence the corresponding region
will scale. In order to take this effect into account, we can calculate
the second moment ( i.e. the variance of pixel locations at the boundaries
). Note that this is analogous to describing a random variable with
its mean and variance which is good enough in many situations.
![]()
Since there are many regions in an
image, we also have to solve a correspondence problem. To solve this problem,
several parameters can be used. First of all, the coarse luminance value
of the region( e.g. 3bit "car" image) can be used. If we assume conservation
of brightness constraint, the object in the next frame must have the coarse
luminance value, although the luminance values of corresponding pixels
may not be exactly the same. Also, since the shape of a object should not
change significantly, the ratio of horizontal and vertical second moments
can be used to discriminate different regions with the same course luminance
value. Additionally, if we assume a high speed sampling rate in time, we
can use absolute values of center of mass and second order moments to solve
the correspondence problem. Since difference between frames should be small,
we confine our search to those that are not too much different. Also, the
number of edge pixels for the regions can be a parameter for the feature.
Notice that the amount of real calculations is fairly small.